Years ago, I started Guild Wars Legacy after it was announced that Guild Wars Guru, the biggest Guild Wars 1 fansite at that moment, was going to shut down. Guru was the biggest source of information, a true treasure trove for the Guild Wars community and we felt that we had to do everything in our possibility to preserve a copy. The owners of Guru, Curse, had promised to keep an archive of the website up and running, but in reality this lasted only a few months before it was permanently shut down.
A few years later, the sister site Guild Wars 2 Guru was also shut down.
In the midst of this, we decided to go ahead and host a copy of Guild Wars Guru that was downloaded by one of the users
of Guild Wars Guru/Legacy. This was a static HTML version of the website, which for such a huge forum contains a TON of
files. In fact, there are about 776673 static HTML files and about 1.1 million files in total in the archive.
That’s a lot and the archive itself is about 78.5 GB big and this does carry quite a cost with it due to the huge amount of
space required. Next to the archive itself, we also host the source .zip files which account for another 75 GB. So in total,
the server reported 162 GB of data.
I have, however, decided to move to a new server and with this, I decided to try and minify this as much as possible.
So, how do you go about minifying a 1.1 million files dataset? I’ll walk you through it.
The ZIP files
The zip-files itself were badly compressed and were, on it’s own, about 75 GB. I feel that it is important to keep these ZIP files available though, since I’ll probably change the original files quite a lot in my quest to minify them.
To make these smaller, I decided to move to a more efficient compression format and I decided to go with my favourite compression tool for this, 7zip.
While the original ZIPs all contained only a fraction of the total archive, I decided to mash it all together for the new archive file. So I unzipped all of them and compressed it heavily (with a huge dictionary size) which allowed me to lower the file size of the archive to a mere 9.65 GB. According to 7zip, it had a final size of 12% of the original size!
I call that a huge win, cutting down more than 50 GB of space in one fell swoop!
The archive itself
Now, when you download a website, you are going to download several things A LOT. You are going to have a lot of repeated contents, and some of those can be stripped out quite well.
In fact, the original file size of the archive was 78.5 GB. Since a lot of that is repeated content, I decided that stripping that out and including it with PHP would save me about 776673 times these lines. So, I tested this out with the DOCROOT and some meta tags:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8" />
<meta name="generator" content="vBulletin 3.8.7" />
I replaced this with the following code:
<?php include('/var/www/archive.guildwarslegacy.com/includes/doctype.php'); ?>
The doctype.php file includes the same content, but with another generator value. The reason for changing the generator value is quite simple: Google spams me with this, saying that it found a vulnerable script on my website that I need to patch asap and the search ranking will get a hit due to this. So, this is why it is getting replaced with another generator tag.
Now, these are only 5 lines in total, so this would save me about 4 lines in total in each of those files. That means that it would remove 3,106,692 lines in total. And that does have a result, because removing just those 5 lines in every file freed up 100 MB in total. That doesn’t seem like much, but every bit helps.
Due to the forum software that was used on Guru, it had a few more… interesting bits. It used something called
vBulletin and it had a LOT of inline CSS that was identical on every page. So I stripped that out as well. I won’t list
it here, since it’s 1123 lines long and this is repeated in every single html file.
So, if we replace this with a single PHP include, we can remove 1122 lines in every html file. That will end up saving a
whopping 871,427,106 lines of code and will reduce the archive significantly. In fact, due to this removal alone, the
archive shrunk to 62.4 GB, so that means that we lowered the archive with 16 GB just by deleting this.
Now, this was by far the biggest chunk of recurring code in the entire archive, but there was quite a lot more that we could remove - the forum was built in a way that it was dynamic, but now it is static HTML. So, I am working on stripping out the search function (since that doesn’t work anyway), I remove the login-boxes and just about everything that I can remove right now in a simple way.
Now, for the most interesting part - how did I actually remove the lines? What tools did I use for this?
Removing the actual lines.
This is actually a lot harder than you might think - search and replace is easy, but when you have a fileset of over 1 million files, it gets hard fast. It’s not an option to do it all manually, and while there are many bulk search and replace tools, they aren’t perfect. I tested a few tools, but the tool I ended up using is called Find and Replace, and in action it looks something like this:
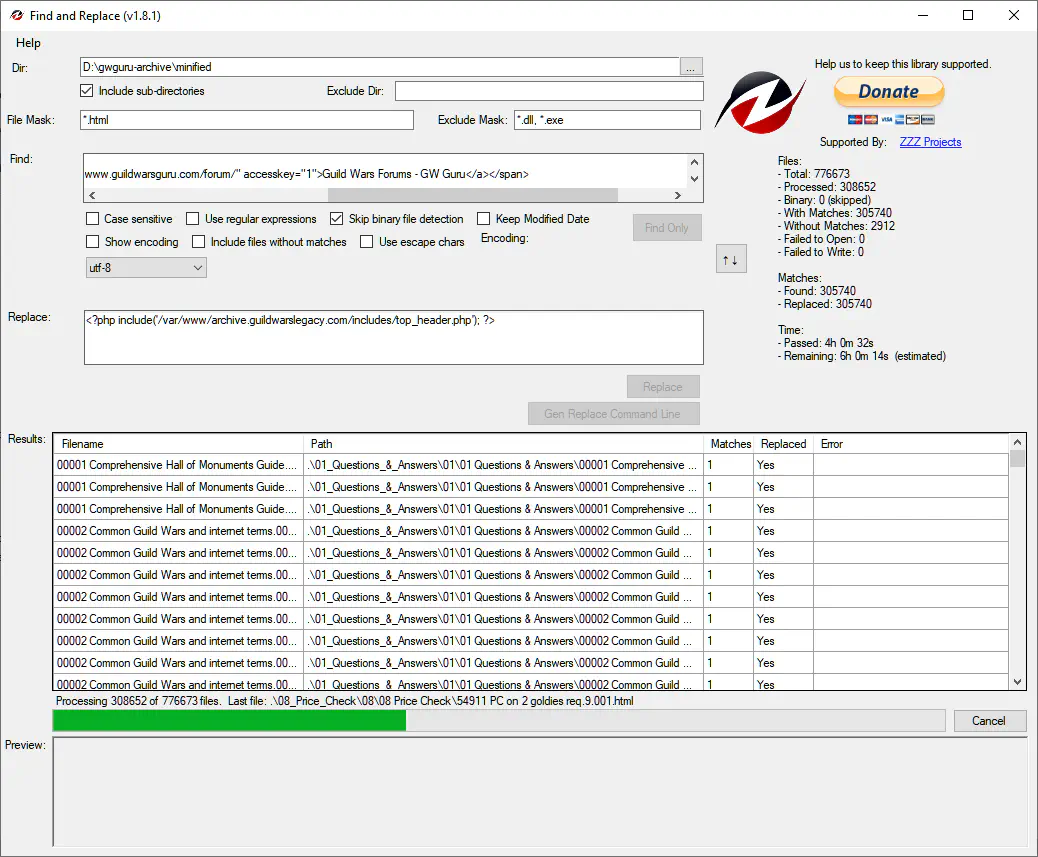
Yes, you see that right - a single run for modifying files takes up more than 9 hours to complete. And often, even longer. While this tool works great, it has a serious drawback and that is that it eats RAM in a rate that would make Chrome jealous:

One thing you have to keep in mind is that you should disable your anti-virus while running this tool, since anti virus software will interfere with this and will give issues. At the least it will slow down the operation enormously, since it likes to scan all actions happening, but on this scale it just slows everything down to a crawl.
But, this is the tool that worked best so far. Since I do like programming, I did dabble in something else…
Programming tools
I was curious if there was a way that wasn’t as resource-hungry to get around this, and I did find one. The code itself isn’t the best I have ever written, and I only used it for the docroot-removal, since it would have made me insane should I have used this for the inline CSS, since this required an IF-block for every line and required unique lines. But, in the interest of sharing things that I have explored, I wanted to share my (badly written) code anyway.
This is written in Golang, I’ll walk you through below on what it does.
package main
import (
"fmt"
"io/ioutil"
"os"
"path/filepath"
"strings"
)
func visit(path string, fi os.FileInfo, err error) error {
if err != nil {
return err
}
if !!fi.IsDir() {
return nil //
}
matched, err := filepath.Match("*.html", fi.Name())
if err != nil {
panic(err)
return err
}
if matched {
read, err := ioutil.ReadFile(path)
if err != nil {
panic(err)
}
//fmt.Println(string(read))
//fmt.Println(path)
if strings.Contains(string(read), "<!DOCTYPE html PUBLIC \"-//W3C//DTD XHTML 1.0 Transitional//EN\" \"http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd\">") {
fmt.Println("replacing string in" + string(path))
newContents := strings.Replace(string(read), "<!DOCTYPE html PUBLIC \"-//W3C//DTD XHTML 1.0 Transitional//EN\" \"http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd\">", "<?php include('/var/www/archive.guildwarslegacy.com/includes/doctype.php'); ?>", -1)
err = ioutil.WriteFile(path, []byte(newContents), 0)
if err != nil {
panic(err)
}
} else if strings.Contains(string(read), "<head>") {
newContents := strings.Replace(string(read), "<head>", "", 1)
err = ioutil.WriteFile(path, []byte(newContents), 0)
if err != nil {
panic(err)
}
} else if strings.Contains(string(read), "<meta http-equiv=\"Content-Type\" content=\"text/html; charset=UTF-8\" />") {
newContents := strings.Replace(string(read), "<meta http-equiv=\"Content-Type\" content=\"text/html; charset=UTF-8\" />", "", 1)
err = ioutil.WriteFile(path, []byte(newContents), 0)
if err != nil {
panic(err)
}
} else if strings.Contains(string(read), "<meta name=\"generator\" content=\"vBulletin 3.8.7\" />") {
newContents := strings.Replace(string(read), "<meta name=\"generator\" content=\"vBulletin 3.8.7\" />", "", 1)
err = ioutil.WriteFile(path, []byte(newContents), 0)
if err != nil {
panic(err)
}
}
}
return nil
}
func main() {
err := filepath.Walk("D:\\gwguru-archive\\minified", visit)
if err != nil {
panic(err)
}
}
It isn’t entirely original code, but I forgot the source. The main issue here is that I’m replacing line-by-line, and I can’t replace a chunk at once. In order to do a full find and replace, I’d first have to scan the entire file and check line-by-line if it matches and if it does, once the scan is done, re-read the file and change the files in it.
How this works is by reading line by line, once it detects a line that starts with DOCTYPE, it will print that it has found
an occurence of the line. If it isn’t found, it will loop through the other else if statements which simply removes the
line.
A way to optimize this is by stopping the scan once it has deleted the last line (the generator), but it was a quick and
dirty script. It ran with a lot less ram-consumption and I’m considering updating this for later on, since it was quite
a bit faster and it did work as intended! Since the lines are quite identical in every file, I might just even detect the
first line and delete everything/before/after.
Some important notices
Working with such a file set comes with drawbacks: it is huge, it takes a ton of time to do even a single thing and worst of all: it’s limiting what you can do. I lost tons of RAM on the moments that I was running this, due to FnR’s tendency to eat RAM. I also lost quite a bit of performance when my anti-virus was enabled.
Next to that, you should NEVER do this on an SSD, since you are doing many read/writes on it, this can burn down an SSD
quite quickly - so I suggest that you put the folder on your HDD. This might limit the IOPS you can do, but since FnR
doesn’t utilize multiple cores (I’ve built an experimental Golang script that did do this), your main limit is what the
FnR program can do.
I ran this on my main computer, mainly because while I could run this on a Linux server, my computer has better specs to
do this. I also didn’t want to start adding in hundreds of line of code in the command line… it would have been too
much of a hassle - in the end, this worked out quite well and it has shrunk the archive considerably, while still allowing
me to expand it by giving me entry points on every page.
The archive is still being worked on, but at the moment that I’m writing this, the archive has shrunk to 60.4 GB and there
is still some space to be saved!
Once this is done, I’ll certainly post the end result here.
- Kev